
Nemrég részt vettem az Önkiszolgáló BI workshop-on (itt írtam erről). Azóta már fel is építettem egy adatbázist, amit nagy megelégedéssel használnak a kollégák. Az építgetés közben azonban szembetalálkoztam egy furcsa jelenséggel, ami nekünk a gyakorlatban sajnos bosszúságot okozott. Ebben a cikkben bemutatom, mi volt ez, és hogyan sikerült áthidalni a problémát.
Az adatbázis
Az adatbázisunk cikkszámonkénti értékesítési adatokat (mennyiség, árbevétel, stb.) és egy cikktörzs táblát tartalmaz. A cikktörzs táblában a cikkszámok különböző szempontok szerint csoportosítása van tárolva (termék kategória, márka, stb.) A két táblát a cikkszám mező kapcsolja össze. Fontos, hogy a cikktörzs táblában több cikkszám van, mint amennyire árbevételünk van az adott időszakban (tartalmaz régi cikkeket, más országokban értékesített cikkeket és technikai cikkszámokat is).
A megfigyelt probléma
A PowerPivot-ra épített pivot táblában olyan cikkek, cikk csoportok is megjelentek, melyekre egyáltalán nem volt értékesítési adat. Ez sok esetben több száz üres, adattal nem rendelkező sort jelent, amik bekeverednek a többi cikk közé:
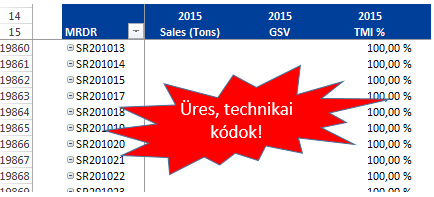
Miért kerülnek be ezek a cikkek a pivot táblába?
Nyomozás
Megfigyeltem, hogy a gyanús cikkeknél csak a olyan mezőben van érték, ami kalkulált mező, ÉS konstans van a formulában!
Készítettem egy kis példát, hogy jobban érthető legyen.
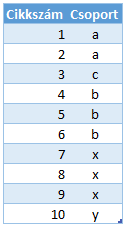
Ez lesz a cikktörzs tábla:
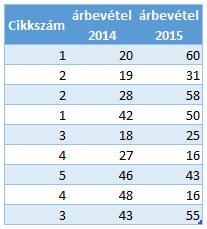
Ez pedig az adat tábla:
Mindkettőt betöltöttem PowerPivot-ba, és a cikkszám mezővel összekapcsoltam.
Látható, hogy a 7, 8, 9 és 10-es számú cikkekre nincs adat – ezek az x és y csoportba tartoznak.
Ezután kalkulált mezőt készítettem az árbevétel növekedés számszerűsítésére:
Növekedés % 1 := DIVIDE( [árbevétel 2015] ; [árbevétel 2014] ; 0 )
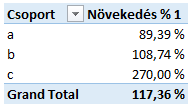
A növekedést cikk csoportonként mutatja a pivot tábla:
Nálunk azonban a növekedés mutatószám definíció szerint a 100%-on felüli részt jelenti, tehát így kell számolnom:
Növekedés % 2 := DIVIDE( [árbevétel 2015] ; [árbevétel 2014] ; 1 ) – 1
Ezzel a mutatószámmal a pivot tábla így néz ki:
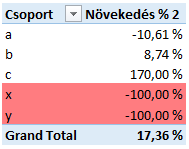
Látható, hogy megjelent az x és y csoport, amire nem volt adat az értékesítési adatok táblában!
A problémát egyértelműen a formula végén található -1 okozza. Felépítettem a kalkulációt IFERROR-ral is:
Növekedés % 3 := IFERROR( [árbevétel 2015] / [árbevétel 2014] – 1 ; 0 )
Ebben az esetben ugyanúgy megjelentek az felesleges sorok.
Csak akkor sikerült kiküszöbölni ezeket a sorokat, ha számítást konstans nélkülivé alakítottam:
Növekedés % 4 := IFERROR( ( [árbevétel 2015] – [árbevétel 2014] ) / [árbevétel 2014] ; 0 )
Mi történt itt?
A táblák közötti kapcsolat (JOIN) segítségével összeállítódik a kalkuláció (virtuális) alaptáblája. Ebben minden cikkszám szerepel, ami megjelenik akár a cikk törzs, akár az adat táblában. Azok a sorok, amelyek üresek (BLANK), vagyis nem szerepelnek az adat táblában, azok nem fognak megjelenni a pivot táblában.
A probléma a kalkulált mezőből ered: a PowerPivot-ban a BLANK + konstans = konstans. Ebben az esetben tehát a kalkuláció az üres sorokra is értéket ad, vagyis ezek benn maradnak a pivot táblában.
Gábor: Ha SQL-ben gondolkodunk, úgy néz ki, mintha a táblákat összekapcsoló JOIN típusa változna meg: mintha INNER JOIN-ból OUTER JOIN lenne. Ez így nem jó, mert olyan kalkulált adatok jelennek meg a végeredményben, amelyek a valóságban nem léteznek – csak azért mert egy bizonyos módon írtuk fel a képletet: ha másképp írjuk fel, akkor ezek a nem létező eredmények nem jelennek meg.
Megoldás
Nos… Nem tudom, miért hasznos ez a furcsa BLANK kezelés, nekem egyenlőre bosszúságot okoz. Szerencsére csak olyan kalkulált mezőket kell felépítenem, ahol a hányadosba be tudom építeni a konstanst – így átalakítva már nem okoz problémát a pivot táblában.
Remélem, másnak is hasznos lesz ez a tapasztalat! Innen letölthetitek a példa fájlunkat is, amiben látjátok a kalkulációt és a pivot táblákat.

Legutóbbi hozzászólások